
支持向量机(Support Vector Machines, SVM)在实际应用中,算是一大分类神器了。原始的支持向量机是一种线性二分类模型,当支持向量机使用一些核技巧之后,可以从本质上变成非线性分类器。区别于感知机模型,线性可分支持向量机利用间隔(两个不同类的支持向量到超平面的距离)最大化求最优分离超平面,求得的解是唯一的。
感知机回顾
从感知机模型我们知道,感知机的目标是只要能找到一个将训练数据集的正样本和负样本完全正确分割开的分离超平面就可以了,并不要求样本能被最大限度地划分,但是这样的话会导致模型的泛化能力不强,比如下左图,直线Y能把A,B两类样本完全分割开,是感知机模型的一个解,如果我们用Y去预测未知的数据,如下右图,$a1,a2$两个数据点实际为类别A,但却被直线Y误判为B类,说明该直线对未知数据的泛化能力并不强。

直观上,下图中的红色直线的划分效果比其他直线的划分效果都要好,因为该直线恰好在两个类的中间,尽量“公平”地远离了两个不同的类别。但是,如何才能找到这样的一个超平面使之能最好地区分正负样本,并且对未见的数据的泛化能力也是最强的呢?这就是支持向量机要解决的问题。

什么是支持向量?
支持向量(Support Vector)的定义其实很简单,其实就是距离超平面最近的样本点,如下图中的$a1,a2,a3$三个点就称为支持向量。

为什么叫支持向量呢,因为所有的训练样本点其实都是以向量的形式表示的(尤其是当属性很多的时候),而上图的划分的超平面,仅仅由$a1,a2,a3$这三个点决定,与其他训练样本点一毛钱关系都没有(这也就是为什么SVM效率贼高的原因)!也就是说我们要找的划分超平面,其实是由这三个向量(vector)来支撑(support)的,因此我们称$a1,a2,a3$这三个点为Support Vector。so,只要找到支持向量,划分超平面也就找到了。

好了,知道了支持向量的概念,我们就可以按照模型→策略→算法 的步骤去求解SVM了。
模型
上面的分析我们已经清楚地知道,我们的模型(目标函数)其实就是一个超平面,这个超平面可以通过如下线性方程来描述:$$w^Tx+b = 0$$
策略
有了模型,还需要有一个恰当的策略(损失函数)来评估模型的分类效果。前面有提到,我们要找的超平面,应该尽可能地离两个不同样本点都远,以保证泛化能力,而在空间中,衡量样本点到划分超平面的远近,很自然会想到用欧式距离来度量。样本空间中,任意一点$x$到超平面$w^Tx+b = 0$的距离可写为:$$d=\frac{1}{||w||}|w^Tx+b|$$
带上类别之后,上面的距离公式可以写成:$$d=\frac{1}{||w||}y_i(w^Tx_i+b)$$ 对于下图类别A中的数据点$a1$,假设,在该点处,与分割超平面平行的超平面为:$w^Tx+b = c$,因为超平面的参数$w$和$b$同时放大或缩小$k(k\neq 0)$倍时,超平面是一样的(比如$2x+4y=6$和参数同时除以2之后的$x+2y=3$)。那么,不妨对$w^Tx+b = c$做一个变换,令$$w \leftarrow \frac{w}{c}$$ $$b \leftarrow \frac{b}{c}$$
所以$a1$点处的超平面可以写成$w^Tx+b = 1$,同理,$a2,a3$处的超平面可以写成:$w^Tx+b = -1$。显然,对于所有的正例(类别A),以及所有的负例(类别B),使得以下不等式成立:

这个时候,我们套上距离的公式,对于两个不同类别的支持向量$a1$和$a2,a3$到超平面的距离之和它可以写成:$$d = \frac{2}{||w||} $$
这里$\frac{2}{||w||} $也称为间隔。

我们的目标是让间隔尽量地大,这样划分超平面对未见数据的预测能力会更强,也就是希望:

因为函数$\frac{2}{||w||}$的单调性与$\frac{1}{2} {||w||}^2$是相反的,所以,最大化$\frac{2}{||w||}$时,相当于最小化$\frac{1}{2} {||w||}^2$,这样,最优化问题可以转化为凸二次规划问题(目标函数是二次的,约束条件是线性的):

so,损失函数就这样被找出来了。
最优化
在求取有约束条件的最优化问题时,为了更容易求解,我们可以使用拉格朗日乘子法将其转化为原问题的对偶问题进行求解。也就是,对于上面式子的每条约束添加拉格朗日乘子$\alpha_i \geq 0$,对应的拉格朗日函数可以写为:

这里的$\alpha=(\alpha 1;\alpha 2;…;\alpha m)$,$\alpha 1$代表第一个不等式的拉格朗日乘子。成功避开约束条件之后,我们就可以更加便利地去求解极值了。对于函数$L(w,b,\alpha)$分别求参数$w$和$b$的偏导数,并令偏导数为0,可以得到:

把等式$w$代入到函数$L(w,b,\alpha)$:

因为

所以可以把等式中的


根据对偶问题的性质,也就是任何一个求极小值的线性规划问题都可以转化为求极大值的线性规划问题。所以:

可以计算出:

这样,最终的模型可以写成:
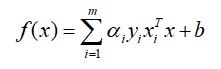
这里还需要注意一下的就是,$x_i^Tx$其实就是向量内积,可以用$<·,·>$表示,也就是:
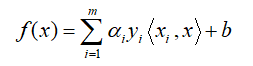
之所以写成这样,是方便后面理解支持向量机是如何使用Kernel进行非线性分类的。上面这个式子可以说是支持向量机核函数的基本形式了。
对于含有不等式约束的最优化,还必须满足KKT条件,也就是:
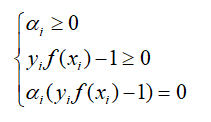
根据条件中的等式$\alpha_i(y_if(x_i)-1)=0$,对于任意的训练样本,总会有$\alpha_i = 0$或者$y_i f(x_i)-1=0$,若$\alpha_i=0$,样本$(x_i,y_i)$不会对损失函数有任何的影响;若$\alpha >0$,则有$y_i f(x_i)-1 =0$,此时,样本$(x_i,y_i)$其实就是支持向量。
后记
基于数据线性可分假设的SVM显然会对噪声很敏感。相对于硬间隔支持向量机,后续会介绍对噪声容忍度稍微强一点的软间隔支持向量机,以及装备核函数之后的强大SVM;总的来说,SVM的基本原理以及使用都是比较简单的,如果只是为了调包,了解基础原理已经可以了。如果是想深入了解,仅仅知道这些还是远远不够的。
公式编辑已弃疗,复杂一点的公式还是截图显示吧,哎。
